5)可能な射をすべて求める
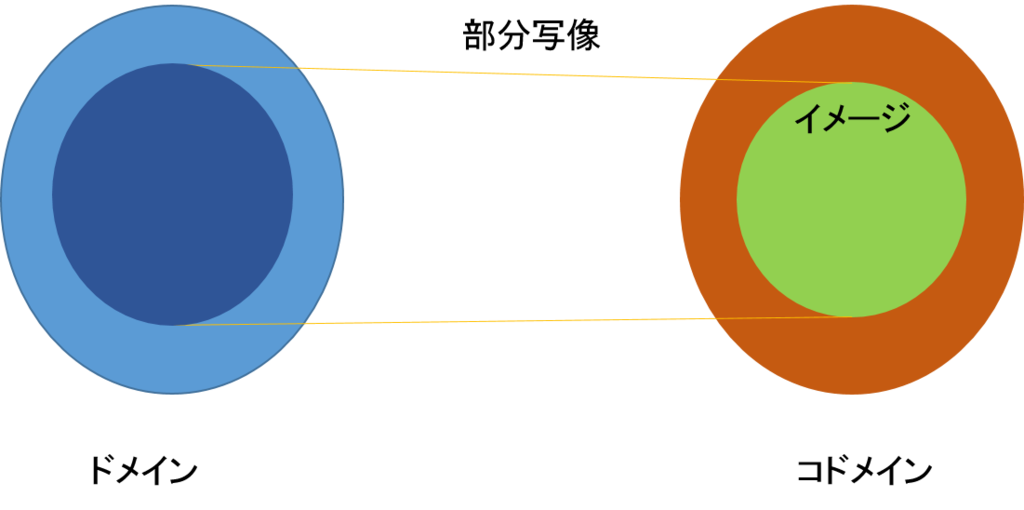
それでは、\(A={1,2,3}\)と\(B={a,b}\)の二つの対象があり、\(A\)をドメイン、\(B\)をコドメインとする射はいくつあるだろうか。ただし、同じ射は含めないとする。正解は下図のように\(2^3=8\)である。

上の結果をHaskellで確かめてみよう。
ドメインとコドメインを次のデータ型\(Domain,Codomain\)で定義しよう。
data Domain = D1 | D2 | D3 deriving (Read, Show)
data Codomain = CA | CB deriving (Read, Show)
可能な射をリストとして出力されるようにしよう。即ち、リストの要素は一つの射に対応するものとする。また、それぞれの射は、ドメインの要素とコドメインの要素の対とする。それぞれの対では、ドメインの要素はその射によって移されるコドメインの要素に移されるものとする(リストが入れ子になっていることに注意)。これを実現したのが、下記のプログラムである。
morphism :: [((Domain, Codomain), (Domain, Codomain), (Domain, Codomain))]
morphism = [((D1,d1), (D2,d2), (D3,d3)) | d1 <- [CA, CB], d2 <- [CA, CB], d3 <- [CA, CB]]
この関数を実行してみよう。
Prelude> :load "Morphism.hs"
[1 of 1] Compiling Main ( Morphism.hs, interpreted )
Ok, modules loaded: Main.
*Main> morphism
[((D1,CA),(D2,CA),(D3,CA)),((D1,CA),(D2,CA),(D3,CB)),((D1,CA),(D2,CB),(D3,CA)),((D1,CA),(D2,CB),(D3,CB)),((D1,CB),(D2,CA),(D3,CA)),((D1,CB),(D2,CA),(D3,CB)),((D1,CB),(D2,CB),(D3,CA)),((D1,CB),(D2,CB),(D3,CB))]
上記の結果で、リストの要素が一つの射を表しているので、可能な射は、
\(( (D1,CA),(D2,CA),(D3,CA) )\)
\(( (D1,CA),(D2,CA),(D3,CB) )\)
\(( (D1,CA),(D2,CB),(D3,CA) )\)
・・・
の8個である。これは、先ほど示したものと一致する。
また、上記の射は、ドメインの要素とそれによって移されるコドメインの要素を示している。最初の射では、\(D1\)を\(CA\)に、\(D2\)を\(CA\)に、\(D3\)を\(CA\)に移す。
6)個数\(m\)のドメインから個数\(n\)のコドメインへの射
一般にドメインの要素数が\(m\)でコドメインの要素数が\(n\)のとき、異なる射の数は\(n^m\)となる。
いくつか確認してみよう。コドメインの要素数が1の時は、異なる射の数は1個である。例えば、ドメインを自然数とすると、射は次のようになる。

コドメインの要素数が0の時は、射は存在しない。
それでは、ドメインの要素数を1としよう。この時は異なる射の数はコドメインの要素の数となる。例えば、コドメインが自然数であったとすると次のようになる(図では\(one,two,three\)まで書いたが、そのあと無限に続く)。

それでは、ドメインの要素数が0の時は、どうであろうか。式からは1となる。そこで、ドメインが空集合の時は、コドメイン全体に移す射が一つあることにする。

それでは、Haskellでドメインの要素数が\(m\)でコドメインのそれが\(n\)の時の関数をすべて求めてみよう。
このプログラムは相当に手ごわいので、少しずつ部品を用意しながら、完成に導こう。今、ドメインの要素数が3であり、要素は順番に\(a1,a2,a3\)となっていったとしよう。これをリストで表すと\([a1,a2,a3]\)となる。一方、コドメインの要素数は2であり、順番に\(b1,b2\)であったとする。ドメインの要素に対してコドメインの要素を対応させることになるが、ドメインの右の方から処理していくことにする。
最初に、行うのは、\(a3\)となる。そこで、\(a3\)を\(b1,b2\)で置き換えたリストを\([[b1],[b2]]\)とする。次に\(a2\)を置き換えて、それを先ほど得たリストの頭にくっつけることにしよう。そうすると、\([[b1,b1],[b1,b1],[b2,b1],[b2,b2]]\)をえる。さらに、\(a1\)についても同じことを行えば、ドメインからコドメインに移す異なる射をすべて得ることができる。
そこで、置き換えられたリストから次の要素も置き換えたリストを作る関数\(addRep\_\)を定義しよう。
addRep_ :: [b] -> [[b]] -> [[b]]
addRep_ [] _ = []
addRep_ _ [] = []
addRep_ (y:ys) (l:ls) = (y:l) : addRep_ [y] ls ++ addRep_ ys (l:ls)
確認してみよう。
*MorphismA> addRep_ [1,2] [[1],[2]]
[[1,1],[1,2],[2,1],[2,2]]
うまく動いているようである。それでは、この操作を左端から右端まで再帰的に順番に行う関数\(morphism\_\)を定義しよう。
morphism_ :: [a] -> [b] -> [[b]]
morphism_ _ [] = []
morphism_ [] ys = [ys]
morphism_ (x:[]) (y:ys) = [y] : morphism_ (x:[]) ys
morphism_ (x:xs) ys = addRep_ ys $ morphism_ xs ys
上の関数で、左端についての処理を行うのが、以下の部分である。
morphism_ (x:[]) (y:ys) = [y] : morphism_ (x:[]) ys
途中の処理は次の部分である。
morphism_ (x:xs) ys = addRep_ ys $ morphism_ xs ys
すでに置き換えの済んでいるリスト\(morphism\_ \ xs \ ys\)に新しい置き換え\(addRep\_ \ ys\)を付け加えている。
正しく動いているかどうか確認してみよう。
*MorphismA> morphism_ [1,2,3] [1,2]
[[1,1,1],[1,1,2],[1,2,1],[1,2,2],[2,1,1],[2,1,2],[2,2,1],[2,2,2]]
*MorphismA> morphism_ ['a', 'b', 'c'] [1,2]
[[1,1,1],[1,1,2],[1,2,1],[1,2,2],[2,1,1],[2,1,2],[2,2,1],[2,2,2]]
うまく動いているようだ。
また、プログラムで
morphism_ [] ys = [ys]
は、空集合に対する射である。次のようになる。
*MorphismA> morphism_ [] [1,2]
[[1,2]]
全体への射となる。
さて、部品が完成したので、これはモジュール\(MorphingA\)としておこう。
module MorphismA (morphism_) where
morphism_ :: [a] -> [b] -> [[b]]
morphism_ _ [] = []
morphism_ [] ys = [ys]
morphism_ (x:[]) (y:ys) = [y] : morphism_ (x:[]) ys
morphism_ (x:xs) ys = addRep_ ys $ morphism_ xs ys
addRep_ :: [b] -> [[b]] -> [[b]]
addRep_ [] _ = []
addRep_ _ [] = []
addRep_ (y:ys) (l:ls) = (y:l) : addRep_ [y] ls ++ addRep_ ys (l:ls)
要素の数が与えられた時は、配列を自動的に作り出して、\(morphism\_\)を呼び出して、可能な関数をリストの列で与える関数\(morphism\)を次のように定義する。
morphism :: (Num b, Num a, Enum b, Enum a) => a -> b -> [[b]]
morphism m n = morphism_ [1..m] [1..n]
これの動作を確認しよう。
*Main> morphism 3 2
[[1,1,1],[1,1,2],[1,2,1],[1,2,2],[2,1,1],[2,1,2],[2,2,1],[2,2,2]]
うまく動いているようである。
上記では、ドメインからコドメインへの射は配列、例えば[1,1,1]、で与えられているが、これをタプル、即ち(1,1,1)、で表すことにしよう。
これは、コドメインの要素数ごとに関数を用意する。要素数が0に対しては\(morphism0、1\)に対しては\(morphism1、2\)に対しては\(morphism2\)のように定義しよう。次のようになる。
morphism0 :: (Num a, Enum a) => a -> [[a]]
morphism0 n = morphism 0 n
morphism1 :: (Num a, Enum a) => a -> [a]
morphism1 n = toPair1 $ morphism_ [1..1] [1..n]
where
toPair1 [] = []
toPair1 (f:fs) = (f !! 0) : toPair1 fs
morphism2 :: (Num a, Enum a) => a -> [(a, a)]
morphism2 n = toPair2 $ morphism_ [1..2] [1..n]
where
toPair2 [] = []
toPair2 (f:fs) = (f !! 0, f !! 1) : toPair2 fs
morphism3 :: (Num a, Enum a) => a -> [(a, a, a)]
morphism3 n = toPair3 $ morphism_ [1..3] [1..n]
where
toPair3 [] = []
toPair3 (f:fs) = (f !! 0, f !! 1, f !! 2) : toPair3 fs
morphism4 :: (Num a, Enum a) => a -> [(a, a, a, a)]
morphism4 n = toPair4 $ morphism_ [1..4] [1..n]
where
toPair4 [] = []
toPair4 (f:fs) = (f !! 0, f !! 1, f !! 2, f !! 3) : toPair4 fs
morphism5 :: (Num a, Enum a) => a -> [(a, a, a, a, a)]
morphism5 n = toPair5 $ morphism_ [1..5] [1..n]
where
toPair5 [] = []
toPair5 (f:fs) = (f !! 0, f !! 1, f !! 2, f !! 3, f !! 4) : toPair5 fs
morphism6 :: (Num a, Enum a) => a -> [(a, a, a, a, a, a)]
morphism6 n = toPair6 $ morphism_ [1..6] [1..n]
where
toPair6 [] = []
toPair6 (f:fs) = (f !! 0, f !! 1, f !! 2, f !! 3, f !! 4, f !! 5) : toPair6 fs
分かりやすいところから、実行してみよう。ドメインとコドメインとも要素数が2の場合は次のようになる。
*Main> morphism2 2
[(1,1),(1,2),(2,1),(2,2)]
これは次のように解釈される。射は4個ある。それらは、(1,1),(1,2),(2,1),(2,2)である。最初の射(1,1)は、ドメインの最初の要素をコドメインの最初の要素に、そして、ドメインの最後の要素をコドメインの最初の要素に移す。ここで、ドメインの要素の順番は適当でよい。コドメインについても同じである。
ドメインの要素数が3になるとどうなるであろうか。
*Main> morphism3 2
[(1,1,1),(1,1,2),(1,2,1),(1,2,2),(2,1,1),(2,1,2),(2,2,1),(2,2,2)]
4では、
*Main> morphism4 2
[(1,1,1,1),(1,1,1,2),(1,1,2,1),(1,1,2,2),(1,2,1,1),(1,2,1,2),(1,2,2,1),(1,2,2,2),(2,1,1,1),(2,1,1,2),(2,1,2,1),(2,1,2,2),(2,2,1,1),(2,2,1,2),(2,2,2,1),(2,2,2,2)]
だいぶ関数が多くなってきた。関数の数を数えてみよう。今得た結果に\(length\)を施すと求めることができる。
*Main> length $ morphism4 2
16
要素数が5と6の時についても求めてみよう。
*Main> length $ morphism4 2
16
*Main> length $ morphism5 2
32
*Main> length $ morphism6 2
64
それでは、ドメインの要素数が1の時の射を求めてみよう。
*Main> morphism1 2
[1,2]
本当は、[(1),(2)]と表示されることを望んだのだが、()がなくても同じということで、省かれている。
ドメインの要素数が1の時の射を求めてみよう。
*Main> morphism0 2
[[1,2]]
*Main> length $ morphism0 2
1
全体に移され、射の総数は1である。
それでは、コドメインの要素数を変えてみよう。1個の場合はどうであろうか。
*Main> morphism0 2
*Main> morphism6 1
[(1,1,1,1,1,1)]
*Main> morphism5 1
[(1,1,1,1,1)]
*Main> morphism4 1
[(1,1,1,1)]
*Main> morphism2 1
[(1,1)]
*Main> morphism1 1
[1]
*Main> morphism0 1
[[1]]
射の数はどれも1であることが確認できる。
それでは0の場合はどうであろうか。
*Main> morphism6 0
[]
*Main> morphism5 0
[]
*Main> morphism4 0
[]
*Main> morphism3 0
[]
*Main> morphism2 0
[]
*Main> morphism1 0
[]
*Main> morphism0 0
[]
個数は0だ。
Haskellでは空集合をデータ型Data.Voidで定義している。その中に、\(absurd\)という関数があって、\(Void\)を任意の型に移している。
Prelude> import Data.Void
Prelude Data.Void> :i Void
data Void
instance [safe] Eq Void
instance [safe] Ord Void
instance [safe] Read Void
instance [safe] Show Void
Prelude Data.Void> :t absurd
absurd :: Void -> a
論理学では\(Void\)は偽の値を持つ。\(Absurd\)の関数を\(if \ Void \ then \ a\)とみなすならば、\(Void\)が偽であることから、\(a\)は何であったもよいことになる。即ち、任意の型でよいことになる。このことを表しているのが、\(absurd\)だが、使う機会はなさそうである。